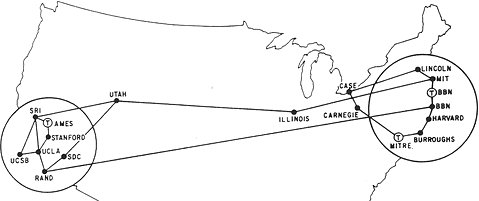
Say we allocate
for the following program: Car-owners who trade in an old car that gets less than
,
and purchase a new car that gets better than
,
will receive a
rebate.
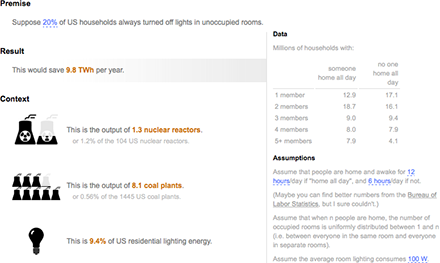
We estimate that this will get
old cars off the road. It will save
of gas (or
worth of U.S. gas consumption.)
It will avoid
CO2e, or
of annual U.S. greenhouse gas emissions.
The abatement cost is per ton CO2e of federal spending, although it’s per ton CO2e on balance if you account for the money saved by consumers buying less gas.
This passage gives some estimates of what the proposal would actually do. But there’s something more going on. Some numbers above are in green. Drag green numbers to adjust them. (Really, do it!) Notice how the consequences of your adjustments are reflected immediately in the following paragraph. The reader can explore alternative scenarios, understand the tradeoffs involved, and come to an informed conclusion about whether any such proposal could be a good decision.
This is possible because the author is not just publishing words. The author has provided a model — a set of formulas and algorithms that calculate the consequences of a given scenario. Some numbers above are in blue. a blue number to reveal how it was calculated. (“It will save ” is a particularly meaty calculation.) Notice how the model’s assumptions are clearly visible, and can even be adjusted by the reader.
Readers are thus encouraged to examine and critique the model. If they disagree, they can modify it into a competing model with their own preferred assumptions, and use it to argue for their position. Model-driven material can be used as grounds for an informed debate about assumptions and tradeoffs.
Modeling leads naturally from the particular to the general. Instead of seeing an individual proposal as “right or wrong”, “bad or good”, people can see it as one point in a large space of possibilities. By exploring the model, they come to understand the landscape of that space, and are in a position to invent better ideas for all the proposals to come. Model-driven material can serve as a kind of enhanced imagination.